互联网广告投放系统中,根据细分人群进行精准投放已经成为事实标准。Facebook、Google、百度、阿里巴巴、腾讯都建立了自己的精准投放系统,各家的实现大同小异,但基本形态都是支持各个维度、各种粒度的人群定位。
以上几家巨头的精准定向系统基本都支持年龄、性别、地域、兴趣等各个维度的标签组合定向,实际线上系统中,涉及的字段数量几千甚至上万个都有可能。我们简单思考一下,如果使用传统关系数据库来支撑此类业务,该怎么做?
传统关系数据库的局限
例如,假设我们有如下数据表:

有广告主指定广告只面向一线城市 30 岁以下喜欢 MOBA 游戏的男性投放,把定向条件改写为 SQL,大致如下:
1 | SELECT * FROM t_user_profile |
有两种解决方案:
- 对每个字段都建立索引。因为字段众多,将面临索引放大的情况,同时因为筛选条件组合的多样化,很有可能不满足最左前缀匹配的原则,导致索引失效,因此这种方案只适合非常简单的定位;
- 不建索引。大型广告企业拥有的用户基本都在亿级,复杂的 SQL 查询将会非常耗时,很难满足实时性的要求,数据库系统将充斥着慢查询,因此这条方案也被 pass。
综上,在广告定向这一场景下,传统关系数据库已不能满足标签随意组合筛选的需求。
搜索引擎与 bitmap
我们不禁把眼光投到搜索引擎身上,因为搜索引擎的强项就是做布尔查询和筛选。我们知道,搜索引擎高效的秘诀之一就是倒排索引。具体到刚刚的例子,我们可以为每个字段值建立倒排,如下图所示:

因为用户在亿级别,如果像上图用 int 存用户 id ,将非常占存储。所以我们考虑用 bitmap 来节省空间,将每个用户 id 作为 bitmap 对应的一位。如下:
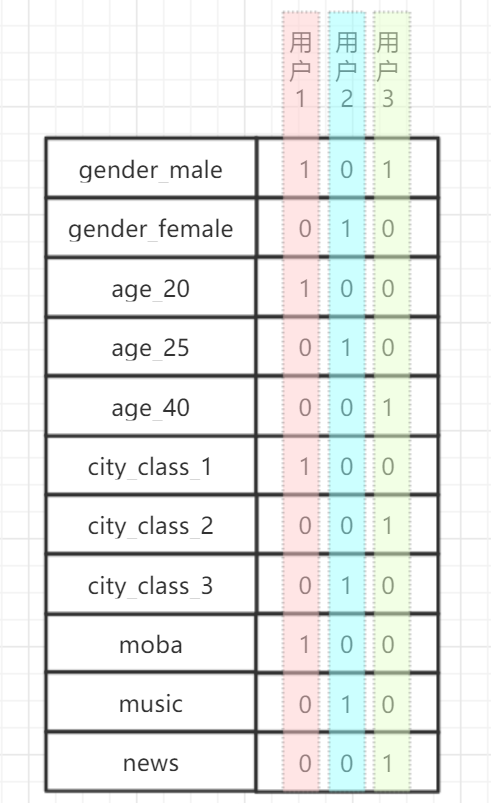
只要某个用户 id 在倒排中出现,则将 bitmap 对应位置为 1(类似机器学习特征处理中的 multi-hot 编码)。回到最初提到的定向场景,我们对所有符合条件的倒排做按位与运算即可筛选出符合条件的定向人群,这是 bitmap 的另一大魔力。实际上,开源的搜索组件基本都会用到 bitmap 。
bitmap 压缩
即使 bitmap 占用的空间只占普通 int 型的八分之一,当用户量多了后也还是会占用不少存储,因此需要对 bitmap 做压缩处理。
常见的 bitmap 压缩技术都是基于 RLE(Run Length Encoding,详见 http://en.wikipedia.org/wiki/Run-length_encoding )。例如 BBC、WAH 以及 EWAH,此外还有非 RLE 的 RoaringBitmap 。综合而言,RoaringBitmap 是其中的佼佼者,因为其拥有更好的随机访问性能。
范围查询
我们再来看图 3 中的倒排索引,可以看到,我们对每个年龄值都做了一个倒排 bitmap。如果要支持筛选 0-30 岁的用户,我们可以对 0-30 间所有数字的倒排做按位或运算。实际业务场景中,可以对连续数值字段做分段,比如年龄分成 0-10、10-18、18-25、25-35 等不同的区间,但是这样会损失部分查询的精准性,比如我们要筛选出 12-22 岁之间的用户,按照这样的区间划分是做不到的。
我们使用区间编码 bitmap ( range-based bitmap ) 来解决精确的范围查询这一问题。请看下面的例子:
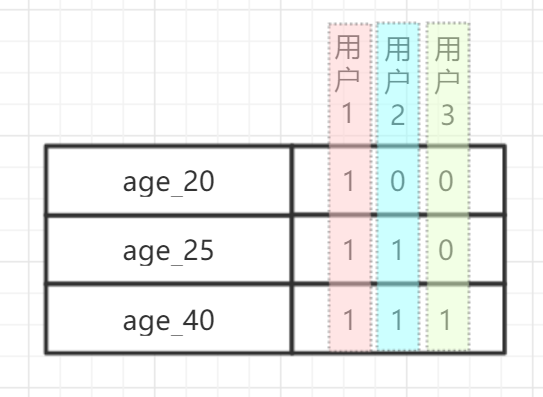
我们依旧对每个数值做一个倒排,对每个用户,除了将该用户在当前数值的位置为 1 ,还将大于该数字的位也置为 1 。结合图 4 来看,只要某一位为 1 ,则它所在那列正下方所有位也要置 1 。从逻辑意义上来说,相当于按行对用户做了累积标记置位。如果我们需要筛选出所有年龄小于 25 岁的用户,只需要数出 25 岁那一行 bitmap 有多少位为 1 即可。计算 bitmap 中 1 的位数是一个非常经典的问题,可以参考 leetcode 191 。而如果需要求出年龄大于 25 岁的用户,则需要先取出所有用户的数目(思考一下,怎么求?)然后减去小于 25 岁的用户即可。
总而言之,通过区间编码,我们可以避免大量的位运算,提高查询效率。
范围查询优化
普通人的年龄在 1 ~ 120 区间内,也就 100 多个取值,像这样每个数字做个倒排似乎没有什么不妥。可是如果我们有个收入字段,收入从 0 ~ 100w 都有可能,岂不是要增加 100w 个 bitmap?可想而知这样生成的 bitmap 将是一个高维稀疏的结构,非常占用存储空间,而且也会造成维度爆炸。针对这种情况,可以引入位切片索引(bit-sliced index)。具体可以参考 6 。
开源组件
基于 bitmap 的搜索,完全可以抽象成一套通用的组件,确实在腾讯内网也有这样的轮子,比如 Hermes 和 Poseidon。外网也有成熟方案,比如 Pilosa 。当然,也可以用当红炸子鸡 ElasticSearch 来完成这个需求。
参考文献
如果你喜欢刨根问底,可以查看下面的文献:
- Daniel Lemire, Owen Kaser, Nathan Kurz, Luca Deri, Chris O’Hara, François Saint-Jacques, Gregory Ssi-Yan-Kai, Roaring Bitmaps: Implementation of an Optimized Software Library, Software: Practice and Experience 48 (4), 2018 https://arxiv.org/abs/1709.07821
- Daniel Lemire, Owen Kaser, Kamel Aouiche, Sorting improves word-aligned bitmap indexes. Data & Knowledge Engineering 69 (1), pages 3-28, 2010. http://arxiv.org/abs/0901.3751
- Owen Kaser and Daniel Lemire, Compressed bitmap indexes: beyond unions and intersections, Software: Practice and Experience 46 (2), 2016. http://arxiv.org/abs/1402.4466
- 漫画:什么是Bitmap算法? https://zhuanlan.zhihu.com/p/54783053 (讲得非常通俗易懂,推荐阅读)
- range-encoded-bitmaps https://www.pilosa.com/blog/range-encoded-bitmaps/
- Rinfret D, O’Neil P, O’Neil E. Bit-sliced index arithmetic[J]. Acm Sigmod Record, 2001, 30(2):47-57. http://www.cs.umb.edu/~poneil/SIGBSTMH.pdf